 |
4000156919 |
|
4000156919 |
��Դ�����`�Bܛ�� ���ߣ��M�N��ܛ�� �l����2017/5/11 �g�[�Δ���5492
�˵��˕r��
�Z���R�e�Ķ˵��˷�����Ҫ�Ǵ��r�����l����׃�������W�j��ģ�ͽY�����]��̫��׃�������w���f���˵��˼��g��Q��ݔ�����е��L���h����ݔ�������L�ȵĆ��}���˵��˼��g��Ҫ�ֳɃ��һ��� CTC ��������һ��� Sequence-to-Sequence ���������y�Z���R�e DNN-HMM �ܘ�����Wģ�ͣ�ÿһ��ݔ�붼����һ���˺�e���˺���Ҫ���͵ĵ������_�����R���ʴ_��
���� CTC ����pʧ�������Wģ�����У�����Ҫ�A�Ȍ��������R��ֻ��Ҫһ��ݔ�����к�һ��ݔ�����оͿ����M��Ӗ����CTC �P�ĵ����A�yݔ���������Ƿ���挍����������������P���A�yݔ��������ÿ���Y���ڕr�g�c���Ƿ��ݔ����������Ì��R��CTC ��ģ��Ԫ�����ػ����֣������������ Blank������һ���Z����CTC ���ݔ�����Ǽ������У�����λ�Ì�����ģ��Ԫ�� Label������λ�ö��� Blank��
Sequence-to-Sequence ����ԭ����Ҫ�����ڙC�����g�I��2017 �꣬Google ���䑪�����Z���R�e�I��ȡ���˷dz��õ�Ч�������~�e�`�ʽ�����5.6%�����D��ʾ��Google �����ϵ�y�Ŀ�����������ֽM�ɣ�Encoder ���a���M�������͘˜ʵ��Wģ�����ƣ�ݔ������Z����̖�ĕr�l���������^һϵ���W�j��ӳ��ɸ����� henc��Ȼ����f�o Attention �M������ʹ�� henc �����W��ݔ�� x ���A�y�ӆ�Ԫ֮�g�Č��R��ʽ���ӆ�Ԫ������һ�����ػ�һ���֡����attention ģ�K��ݔ�����f�o Decoder������һϵ�м��O�~�ĸ��ʷֲ�������ڂ��y���Z��ģ�͡�
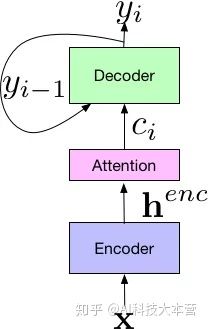
�˵��˼��g��ͻ�ƣ�������Ҫ HMM ���������Ȳ���B��׃�������nj��Z���R�e������ģ�K�yһ���W�jģ�ͣ�ʹ�Z���R�e���������Ρ�����Ч�����ʴ_�ķ���lչ��
�Z���R�e�ļ��g�F��
Ŀǰ�������Z���R�e���߀���� 3 �����ֽM�ɣ��Wģ�͡��Z��ģ�ͺͽ�a������Щ���Ҳ����ǰ��̎���ͺ�̎�����S�����N����W�j�Լ��˵��˼��g���d���Wģ���ǽ�����dz����T�ķ��I�綼�����l���Լ��µ��Wģ�ͽY����ˢ�¸�����������R�eӛ䛡����������Z���R�e�ď��s�ԣ��������Wģ�͵��о��Mչ��������һЩ�����������Ǹ�������s���W�j���g�ں϶˵��˼��g��
2018�꣬�ƴ�Ӎ�w������ȫ���о��e�W�j��DFCNN����DFCNN ʹ�ô����ľ��eֱ�ӌ������Z����̖�M�н�ģ����Ҫ���b�ˈD���R�e�ľW�j���ã�ÿ�����e��ʹ��С���e�ˣ����ڶ������e��֮���ټ��ϳػ��ӣ�ͨ�^�۷e�dz�����e�ػ��ӌ����Ķ����Կ�������Ěvʷ��Ϣ��
2018�꣬������� LFR-DFSMN��Lower Frame Rate-Deep Feedforward Sequential Memory Networks����ԓģ�͌��͎����㷨�� DFSMN �㷨�M���ںϣ��Z���R�e�e�`�������һ�����g���� 20%����a�ٶ����� 3 ����FSMN ͨ�^�� FNN ���[������һЩ�ɌW����ӛ��ģ�K���Ķ�������Ч�Č��Z�����L�r���P���M�н�ģ���� DFSMN ��ͨ�^���D������ӾW�j���ݶ���ʧ���}������Ӗ��������ӵľW�j�Y����
2019 �꣬�ٶ��������ʽ�༉�Ľؔ�ע����ģ�� SMLTA��ԓģ������ LSTM �� CTC �Ļ��A��������ע�����C�Ɓ��@ȡ�������ЌӴε���������Ϣ��������ʽ��ʾ����ֱ�ӌ��Z���M��һ��СƬ��һ��СƬ�ε�������a���༉��ʾ�ѯB����ע����ģ�ͣ��ؔ��t��ʾ���� CTC ģ�͵ļ����Ϣ�����Z���и��һ��һ��СƬ�Σ�ע����ģ�ͺͽ�a�������@ЩСƬ����չ�_���ھ��Z���R�e���ϣ�ԓģ�ͱȰٶ���һ�� Deep Peak2 ģ���������� 15% �����ܡ�
�_Դ�Z���R�e Kaldi �ǘI���Z���R�e��ܵĻ�ʯ��Kaldi ������ Daniel Povey һֱ�Ƴ���� Chain ģ�͡�ԓģ����һ�N����� CTC �ļ��g����ģ��Ԫ����ڂ��y�Ġ�BҪ�����w��һЩ��ֻ�Ѓɂ���B��һ����B�� CD Phone����һ���� CD Phone �Ŀհף�Ӗ���������õ��� Lattice-Free MMI Ӗ����ԓģ�ͽY�����Բ��õ͎��ʵķ�ʽ�M�н�a����a���ʞ���y�W�j�Wģ�͵�����֮һ�����ʴ_������ڂ��yģ���зdz��@����������
�h���Z���R�e���g��Ҫ��Q�挍���������m���x���˙C�΄Ռ�Ԓ�ͷ��յĆ��}���� 2015 ���Ժ��_ʼ�d��ļ��g�������h���Z���R�e��Q�ˏ��s�h���µ��R�e���}�������ܼҾӡ�������܇�����ܕ��h�����ܰ����Ȍ��H�����Ы@���ˏV�����á�Ŀǰ�����h���Z���R�e�ļ��g�����ǰ����̖̎���ͺ���Z���R�e������ǰ�����������L�����ȥ��푡������γɵ���̖̎�������Z����������Ȼ�������˵��Z���R�e�����M���R�e��
�Z���R�e����ɂ����g���֣��Z��ģ�ͺͽ�a����Ŀǰ�������]��̫��ļ��g׃�����Z��ģ������߀�ǻ��ڂ��y�� N-Gram �������mȻĿǰҲ���W�j���Z��ģ�͵��о������ڌ�������Ҫ߀�Ǹ������ں�̎���m�e����a���ĺ���ָ�����ٶȣ��I��ֶ��ǰ����o�B��a�ķ�ʽ�M�У������Wģ�ͺ��Z��ģ�͘���� WFST �W�j��ԓ�W�j���������п���·������a������ԓ���g�M���������^�̡�����ԓ��Փ�������죬������ǹ��̃����Ć��}�����Բ�Փ�njW�g߀�Ǯa�IĿǰ�Pע���^�١�
�Z���R�e�ļ��gڅ��
�Z���R�e��Ҫڅ���h�������ںϻ��ķ���lչ�������h���ɿ���߀�кܶ��y�c�]��ͻ�ƣ������݆�������������s�Ȉ���߀�д�ͻ�ƣ�߀�������^�����е������x�ȼ��g���µļ��g��ԓ�ص�Q�@Щ���}���C�� �X�h����ĸ�֪�������@���܃H�Hֻ���㷨���M������Ҫ�����a�I朵Ĺ�ͬ���g�����������������M�Ă�����������������оƬ��
�Ώ��h���Z���R�e���g��������Ȼ���ںܶ����𣬰�����
��1�����������g���������ȷǾ���ʧ��Ĵ��ڣ��μ�������̖̎���ֶκ��y���������Ƀ����@Ҳ��K���Z������ϵ�y���ƏV���F�еĻ�����ȌW���Ļ��������g���]�п��]��λ��Ϣ��ֱ����ȡ���Ǹ����l���ϵ����棬�ܷ�������ȌW�����Ǿ���ʧ���M�ДM�ϣ�ͬ�r�Y����̖̎���ֶο�����һ���õķ���
��2�����µ��Z���R�e���д�ͻ�ơ���̖̎�����L̎�����Ԇ��}����ȌW�����L̎���Ǿ��Ԇ��}�������H���}һ���Ǿ��ԺͷǾ��ԵįB�ӣ����һ���ǃ����ںϲ��п��ܸ��õؽ�Q���µ��Z���R�e���}��
��3�������ɂ����}�Ĺ�����Ŀǰ����ȌW���H�õ����Z����̖�����l����������Ϣ�����������Z����̖����λ��Ϣ�������nj��ڶ�ͨ�����ԣ������ȌW�����õ�������λ��Ϣ������δ����һ������
��4�����⣬���^�ٔ���������r�£����ͨ�^�w�ƌW���õ�һ���õ��Wģ��Ҳ���о��ğ��c�������緽���R�e������һ�����^�õ���ͨԒ�Wģ�ͣ�������������ķ��Ԕ����õ�һ���õķ����Wģ�ͣ���������@�c���O��Uչ�Z���R�e�đ��÷������@�����ѽ�ȡ����һЩ�Mչ�����������һЩӖ�����ɣ����x�K�OĿ��߀��һ����ࡣ
��5���Z���R�e��Ŀ�����C�����������������D�Q�����ֲ�������K��Ŀ�ġ���Ό��Z���R�e���Z�x����Y������������δ��������Ҫ��һ�������Z���R�e��� LSTM �ѽ����]���Z���Ěvʷ�r����Ϣ�����Z�x������Ҫ����Ěvʷ��Ϣ�����Ў����������Ό����������ĕ�Ԓ��Ϣ���f�o�Z���R�e������һ���y�}��
��6���C�� ������Z�ԣ��H������Ϣ߀������늟����š��@Щ��������ֶΣ���һ����Ȼ��Ҫ�ں���һ��ֻ���@�әC�����ܸ�֪������挍��Ϣ���@�ǙC���܉�W�����֪�R��ǰ��l�������ң��C����ȻҪ��Խ�����٣��܉�������������磬 ����� ���������硣
��Դ�����`�B �gӭ��������
��һ�����£����gһ�����Á��������������ж���£�һ��
��һ�����£��Z���R�e���g��ʷ������