 |
4000156919 |
|
4000156919 |
��Դ�����`�Bܛ�� ���ߣ��M�N��ܛ�� �l(f��)����2018/3/3 �g�[�Δ�(sh��)��4421
�Z���R�e��ͨ���Q���Ԅ��Z���R�e��Ӣ����Automatic Speech Recognition���s���� ASR����Ҫ�nj�����Z���е��~�R��(n��i)���D(zhu��n)�Q��Ӌ��C���x��ݔ�룬һ�㶼�ǿ���������ı���(n��i)�ݣ�Ҳ�п����Ƕ��M�ƾ��a�����ַ����С����ǣ��҂�һ��������Z���R�e�䌍���ǪM�x���Z���D(zhu��n)���ֵ��^�̣����Q�Z���D(zhu��n)�ı��R�e�� Speech To Text, STT �������m���@�Ӿ����c�Z���ϳ�(Text To Speech, TTS )����������
�Z���R�e��һ��ں϶��W��֪�R��ǰ�ؼ��g�����w�˔�(sh��)�W�c�y(t��ng)Ӌ�W���W�c�Z�ԌW��Ӌ��C�c�˹����ܵȻ��A�W�ƺ�ǰ�،W�ƣ����˙C��Ȼ�������g�е��P�I�h(hu��n)��(ji��)�����ǣ��Z���R�e���Q���ԁ��İ낀�����o��һֱ�]���ڌ��H�����^�̵õ��ձ��J�ɣ�һ�����@�c�Z���R�e�ļ��gȱ�����P�����R�e���Ⱥ��ٶȶ��_�������H���õ�Ҫ����һ���棬�c�I(y��)�猦�Z���R�e�������^�����P�����H���Z���R�e�c�I�P����˻��|�����ȑ����ں��Pϵ����������Pϵ��
��ȌW�����g�� 2009 ���d��֮���ѽ�(j��ng)ȡ�����L���M�����Z���R�e�ľ��Ⱥ��ٶ�ȡ�Q�ڌ��H���íh(hu��n)�������ڰ��o�h(hu��n)�����˜ʿ�������Ҋ�~�R�����µ��Z���R�e���ѽ�(j��ng)���^ 95%����ζ���߂����c�����µ��Z���R�e���������@Ҳ���Z���R�e���g��ǰ�l(f��)չ���^����ԭ��
�S�����g�İl(f��)չ���F(xi��n)�ڿ��������ԡ����Ȉ����µ��Z���R�eҲ�_���˿��à�B(t��i)���e���h���Z���R�e�ѽ�(j��ng)�S������������d��ɞ�ȫ�����M����I�������ɹ��ļ��g֮һ�������Z�������ṩ�˸���Ȼ��������������Ч�Ĝ�ͨ��ʽ���Z���ض����ɞ�δ������Ҫ���˙C���ӽӿ�֮һ��
��Ȼ����ǰ���g߀���ںܶ�㣬�猦�ڏ��������h�������ɔ_�����Z�N�����~�R�Ȉ����µ��Z���R�e߀��Ҫ�ܴ�����������⣬�����Z���R�e���x���Z���R�eҲ�Ǯ�ǰ��Ҫ���c��Q�Ć��}���mȻ�Z���R�e߀�o�������o�����I�o������Ⱥ�đ��ã��������ُđ��Ì��`���҂�������һЩϣ����
��ƪ�����ļ��g�ͮa(ch��n)�I(y��)�ɂ��Ƕȁ����һ���Z���R�e�l(f��)չ�Ěv�̺ͬF(xi��n)�������һЩδ��څ�ݣ�ϣ�������������p���g�ˆT�˽��Z���ИI(y��)�����ܮa(ch��n)���dȤͶ�����@���ИI(y��)��
�Z���R�e�ļ��g�v��
�F(xi��n)���Z���R�e�����ݵ� 1952 �꣬Davis ���������������ϵ�һ�����R�e 10 ��Ӣ�Ĕ�(sh��)�ְl(f��)���Č��ϵ�y(t��ng)���Ĵ���ʽ�_�����Z���R�e���M�̡��Z���R�e�l(f��)չ�������ѽ�(j��ng)�� 70 ���꣬���ļ��g�����Ͽ��Դ��w�֞������A�Ρ�
�D�Ǐ� 1993 �굽 2017 ���� Switchboard ���Z���R�e�ʵ��Mչ��r���ĈD��Ҳ���Կ��� 1993 �굽 2009 �꣬�Z���R�eһֱ̎�� GMM-HMM �r�����Z���R�e������������������ 2000 �굽 2009 ���Z���R�e�ʻ���̎��ͣ����B(t��i)��2009 ���S����ȌW�����g���e�� DNN ���d���Z���R�e���׃?y��u)?DNN-HMM���Z���R�e�M���� DNN �r�����Z���R�e�����ʵõ����@��������2015 ���Ժ����ڡ��˵��ˡ����g�d���Z���R�e�M���˰ٻ��R�ŕr�����Z���綼��Ӗ����������s�ľW(w��ng)�j��ͬ�r���ö˵��˼��g�Mһ������������Z���R�e�����ܣ�ֱ�� 2017 ��ܛ�� Swichboard ���_���~�e�`�� 5.1%���Ķ��Z���R�e�Ĝʴ_���״γ�Խ�������Ȼ�@����һ�����l���µČ��Y����߀�������ձ�����ԡ�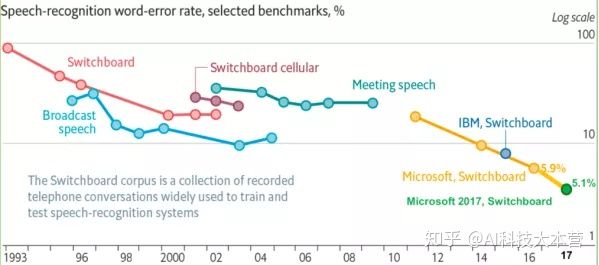
GMM-HMM�r��
70 ������Z���R�e��Ҫ������С�~�R���������~�R�e���棬ʹ�õķ���Ҳ��Ҫ�Ǻ��ε�ģ��ƥ�䷽������������ȡ�Z����̖��������������(sh��)ģ�壬Ȼ�yԇ�Z���c����ģ�兢��(sh��)�M��һһ���^��ƥ�䣬ȡ���x����Ęӱ����������~��ע��ԓ�Z����̖�İl(f��)����ԓ��������Q�����~�R�e����Ч�ģ������ڴ��~�R�������ض����B�m(x��)�Z���R�e�͟o�ܞ�������ˣ��M�� 80 ������о�˼·�l(f��)�����ش�׃�����Ă��y(t��ng)�Ļ���ģ��ƥ��ļ��g˼·�_ʼ�D(zhu��n)����ڽy(t��ng)Ӌģ�ͣ�HMM���ļ��g˼·��
HMM ����Փ���A�� 1970 ��ǰ����ѽ�(j��ng)�� Baum ���˽����������S���� CMU �� Baker �� IBM �� Jelinek ���ˌ��䑪�õ��Z���R�e���С�HMM ģ�ͼٶ�һ�����غ��� 3 �� 5 ����B(t��i)��ͬһ��B(t��i)�İl(f��)��������(w��n)������ͬ��B(t��i)�g�ǿ�����һ�������M�����D(zhu��n)��ijһ��B(t��i)�������ֲ������ø���ģ�́�������ʹ����V����ģ���� GMM����� GMM-HMM ����У�HMM ���������Z���Ķ̕rƽ��(w��n)�ĄӑB(t��i)�ԣ�GMM �Á����� HMM ÿһ��B(t��i)��(n��i)���İl(f��)��������
���� GMM-HMM ��ܣ��о���������N���M��������Y����������Ϣ�ĄӑB(t��i)ؐ�~˹�������^(q��)����Ӗ�����������m��Ӗ��������HMM/NN ���ģ�ͷ����ȡ��@Щ���������Z���R�e�о��a(ch��n)�������hӰ푣�������һ���Z���R�e���g�Įa(ch��n)�������˜ʂ䡣�������o 90 ����Z���R�e�Wģ�͵ą^(q��)����Ӗ���ʄt��ģ�����m������������Ժ��ں��Lһ��(n��i)�Z���R�e�İl(f��)չ���^�������Z���R�e�e�`���Ǘl��һֱ�]�����@�½���
DNN-HMM�r��
2006�꣬Hinton ���������žW(w��ng)�j��DBN������ʹ�������(j��ng)�W(w��ng)�j��DNN���о��ď��K��2009 �꣬Hinton �� DNN �������Z�����W��ģ���� TIMIT �ϫ@���ˮ��r��õĽY����2011 ��ף�ܛ�о�Ժ���ᗝ�������ְ� DNN ���g�������˴��~�R���B�m(x��)�Z���R�e�΄��ϣ�������Z���R�e�e�`�ʡ��Ĵ��Z���R�e�M�� DNN-HMM �r����
DNN-HMM��Ҫ���� DNN ģ�ʹ���ԭ���� GMM ģ�ͣ���ÿһ����B(t��i)�M�н�ģ��DNN �����ĺ�̎�Dz�����Ҫ���Z����(sh��)��(j��)�ֲ��M�м��O�����������Z��ƴ���ְ������Z���ĕr��Y����Ϣ��ʹ�Ì��ڠ�B(t��i)�ķ�����������@������ͬ�rDNN߀���Џ���h(hu��n)���W���������������������Ϳ����������ԡ�
�����f��DNN ���ǽo��ݔ���һ�������������Ġ�B(t��i)���ʡ������Z����̖���B�m(x��)�ģ����H�������ء�����(ji��)�Լ��~֮�g�]�����@��߅�磬�����l(f��)���λ߀���ܵ������ĵ�Ӱ푡��mȻƴ������������������Ϣ���������Z����f߀�Dz����f�w��(j��ng)�W(w��ng)�j��RNN���ij��F(xi��n)����ӛס�����vʷ��Ϣ���������ڌ��Z����̖����������Ϣ�M�н�ģ��
���ں��ε� RNN �����ݶȱ�ը���ݶ���ɢ���}���y��Ӗ�����o��ֱ�ӑ������Z����̖��ģ�ϣ���ˌW���Mһ��̽�����_�l(f��)���˺ܶ��m���Z����ģ�� RNN �Y���������������ľ��� LSTM ��LSTM ͨ�^ݔ���T��ݔ���T���z���T���Ը��õĿ�����Ϣ�����Ӻ͂��f�������L�̕rӛ���������mȻ LSTM ��Ӌ����s�ȕ��� DNN ���ӣ��������w���ܱ� DNN ������ 20% ���ҷ�(w��n)��������
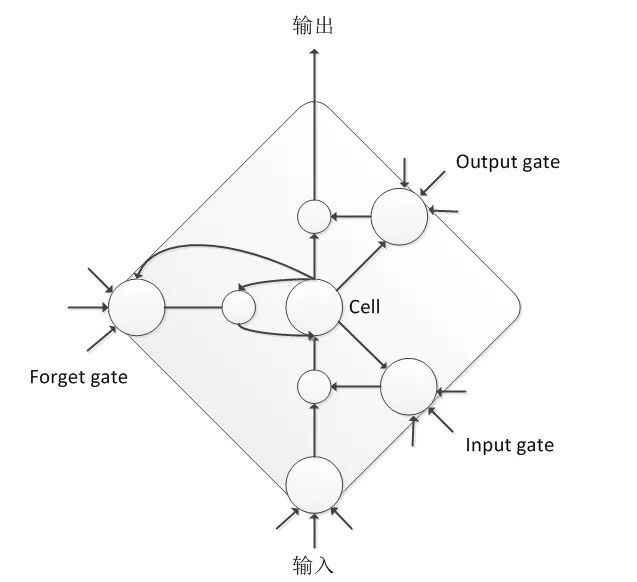
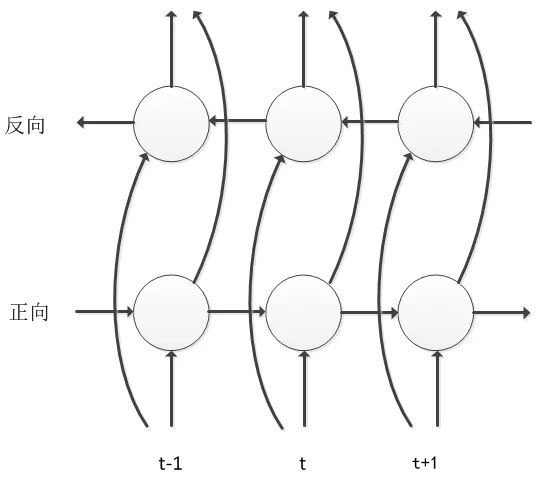
BLSTM ���� LSTM ���A�������Mһ�����M�����H���]�Z����̖�Ěvʷ��Ϣ����ǰ����Ӱ푣�߀Ҫ���]δ����Ϣ����ǰ����Ӱ푣������W(w��ng)�j���ؕr�g�S��������ͷ���ɂ���Ϣ���f�^�̣��@��ԓģ�Ϳ��Ը���ֿ��]�����Č��ڮ�ǰ�Z��Ӱ푣��܉�O������Z����B(t��i)��Ĝʴ_�ʡ�BLSTM ���]δ����Ϣ�Ĵ��r����Ҫ�M�о��Ӽ����£�ģ��Ӗ�����Ք��ٶȱ��^����ͬ�rҲ��������a�����t�������@Щ���}���I(y��)�ö��M���˹��̃�(y��u)���c���M����ʹ�F(xi��n)����Ȼ�кܶ��˾ʹ�õĶ���ԓģ�ͽY����
�D���R�e��������ģ�;��� CNN�����Z����̖�ĕr�l�DҲ���Կ�����һ���D����� CNN Ҳ�����뵽�Z���R�e�С�Ҫ������Z���R�e�ʣ�����Ҫ�˷��Z����̖�����R�Ķ����ԣ������fԒ���������fԒ����̎�ĭh(hu��n)�����ɼ��O��ȣ��@Щ�����Զ����Եȃr����N�V�����c�Z����̖�ľ��e���� CNN �ஔ���OӋ��һϵ�о��оֲ��Pע���ԵĞV��������ͨ�^Ӗ���W���õ��V�����ą���(sh��)���Ķ��Ķ����Ե��Z����̖�г�ȡ����׃�IJ��֣�CNN ���|(zh��)��Ҳ���Կ����Ǐ��Z����̖�в����ȡ������һ���^�̡�CNN ����ڂ��y(t��ng)�� DNN ģ�ͣ�����ͬ������r�£�ǰ�ߵą���(sh��)�����١�
�C�����������ڽ�ģ�������f��DNN �m������ӳ�䵽�������g��LSTM �����L�̕rӛ��������CNN ���L�p���Z����̖�Ķ����ԣ����һ���õ��Z���R�eϵ�y(t��ng)���@Щ�W(w��ng)�j�ĽM�ϡ�
��Դ�����`�B �gӭ��������
��һ�����£����gһ�����Á��������������ж���£�һ��
��һ�����£��Z���R�e���g��ʷ������